这里主要分析Java后端技术栈常用框架的源码(后面也会考虑加入Go、Rust技术栈),从整体到局部探究内部工作原理,并输出可视化流程图。
源码分析输出主要为Drawio流程图(.drawio文件)和 Markdown文档,以流程图为主(主要展示框架数据结构和主流程),Markdown文档作为补充,详细内容参考docs。
这里的流程图不是常规流程图,实际是借鉴的时序图的编排方式,另外还添加了重要类的UML图(UML:体现数据结构 ,流程:体现算法, UML比流程更重要)。
个人认为读源码(不一定是框架源码)是每个程序员都应该养成的习惯,尤其是在做架构设计或方案设计时,如果对某个业务不是很熟悉,第一步应该做的是检索一些开源实现,快速过一遍源码,梳理业务开发中需要考虑哪些设计要点、有哪些实现方式、不同实现方式的优缺点等等,见到很多优秀的程序员都是这么做的,兼顾效率与质量,一些框架也会互相借鉴优点。
后面列举的框架并非都分析过源码(心有余而力不足),有些只是计划,已经分析过源码的都有流程图链接。
有些分析流程图之前记录在其他仓库后续会转移到这里,慢慢补充吧。
-
语言
JDK 一些类的源码少于2000行的一般没必要画流程图,数据结构和逻辑不画图也能梳理清楚,时间久了忘记了重新看也花不了多长时间。
-
JVM
-
HotSpot
已经搭建好了源码调试环境(参考仓库:jvm-debug),但是看JVM源码需要很多操作系统系统编程、内核方面的知识,不是短时间就能把整个流程看明白的,所以暂停了。还是碰到问题先针对性地看对应的代码块吧,更简单些。
源码流程图:
-
jvm8-hotspot.drawio (未完成)
-
java-exec-process.drawio (流程概要)
-
里面有些错误,TODO 修改。
不过Github上有一些简单JVM开源实现,可以参考下以加深对JVM的理解,这里只分析星数最高的一个实现mini-jvm。
-
-
代码量较小,很容易理解。不过也仅仅只包含一些很核心的功能实现(.class文件解析、类加载、实例化、Native方法、方法调用、异常处理),像GC、多线程、双亲委托、JIT优化等等都没有。
其实感觉对深入理解JVM帮助不大,但是比较适合初学者,比单纯啃几本干巴巴的JVM书籍好太多了。
Github Repo:
源码流程图:
-
-
并发
-
AbstractQueuedSynchronizer
源码流程图:
-
ReentrantLock
源码流程图:
-
源码流程图:
-
ThreadPoolExecutor
-
源码流程图:
-
源码流程图:
-
-
容器类
之前都是写的 Markdown文档,TODO 补充流程图。
-
IO
-
NIO
源码流程图:
注意即使是使用NIO这种非阻塞模型,也不意味着你的服务一定是非阻塞的。因为NIO模型仅仅是为了支持使用较少的线程处理大量并发请求,它说的非阻塞是说借助select线程避免当通道没有数据时阻塞Channel读写线程执行(这个Channel没有数据可以去处理其他Channel就绪的数据);业务服务是否阻塞还取决于业务线程读取Channel读线程返回的值的方式,比如Channel线程读取到请求数据后还需要交给业务线程处理,如果业务线程还是使用 FutureTask 这种方式读取返回值那就是阻塞的,如果使用 Callback Promise 这些方式读取返回值就是非阻塞的。
总之 NIO 非阻塞是说的是不会阻塞 Channel 读写线程,响应式Web框架中服务非阻塞则是说服务中所有线程读写都不会阻塞,包括 Channel读写线程。看响应式框架(比如Reactor )
Tomcat 8.x 默认使用 NIO 处理请求但是不妨碍它 “读请求体”、“写响应头”、“写响应体” 依然是阻塞的。
-
-
Reference
源码流程图:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
源码流程图:
原理简述:
本质是一个 WebFlux 应用,内部处理逻辑和 Spring MVC 也有点类似,主要也是定义一组请求处理映射(用于定义路由处理,路由包括一组断言和过滤器),通过断言进行请求与路由的匹配,通过路由的过滤器对请求进行处理(比如:修改路径、进行转发等)。
-
Zuul
{kind=link}
-
Dubbo
源码代码量很大,部分组件拆开。
-
Dubbo主流程
源码流程图:
- dubbo3.drawio (尚未完成)
-
源码流程图:
-
-
Feign
-
Grpc
-
Thrift
{kind=link}
-
Ribbon
源码流程图:
-
Spring Cloud LoadBalancer
源码流程图:
{kind=link}
-
线程间高性能低延迟消息传递框架, 4.x 和 3.x 源码变化还是挺大的。
源码流程图(4.x):
-
Kafka
-
源码流程图:
- rocketmq.drawio
- NameServer: rocketmq-NameServer.drawio.png
- Broker: rocketmq-Broker.drawio.png
- Producer: rocketmq-Producer.drawio.png
- Consumer: rocketmq-Consumer.drawio.png
- rocketmq-messagestore.drawio (消息存储服务原理)
- MessageStore: rocketmq-messagestore.drawio.png
- transaction-message.drawio (事务消息原理)
- transaction-message.drawio.png
关键问题(下面问题详细参考文档 rocketmq.md):
-
同步发送&消费原理
-
顺序消息原理
这个问题实现原理其实挺复杂的(整个流程涉及的源码很多),网上基本没有找到能解释清楚且全面的,个人调试源码很久得出下面结论:
需要满足四点:顺序生产(一组顺序消息需要使用一个生产者实例生产,以避免乱序写入消息队列)、写入同一消息队列、同一消息队列的消息总是发给同一个消费者实例(由消费者负载均衡策略保证)、顺序消费(顺序消息支持单消费者多线程并发消费,通过锁保证消费顺序性),简单几句话说不清,参考文档。
-
消息消费失败重试&死信队列机制
直接参考流程图,这两个问题不算复杂。
-
RocketMQ 消息消费到底是推还是拉
其实是推拉结合的方式,流程简述就是:消费者向Broker发送拉取请求(Netty请求),Broker收到消息后会判断队列中是否有消息,有则批量推送给消费者,没有则将请求缓存起来,待有消息后再推送给被缓存的请求来源消费者,并清除缓存的请求; Netty客户端监听到 Broker 响应后消费消息,消费完成后再发出新的拉取请求。
这样既可以避免拉模式的无间隔轮询空转或有间隔轮询的处理延迟问题,也能避免推模式推送速度大于消费者消费速度导致消息在客户端堆积的问题。
- rocketmq.drawio
-
RabbitMQ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
Elastic-Job
-
XXL-Job
源码流程图:
-
任务执行器工作流程。
-
任务管理器工作流程。
{kind=link}
{kind=link}
-
Jetty
-
Netty
源码流程图:
-
关于 Netty Pipeline 中各种 ChannelHandler 的调用顺序、触发方式解析参考后面 RocketMQ 流程图。
好久之前画的图,UML部分数据结构依赖关系不清晰,流程部分一次完整的请求流程处理过程也不是很清晰,需要重画。
细节问题分析:
-
实际多用Reactor主从多线程模型,RocketMQ 中 NettyRemotingServer 就是Reactor主从多线程模型。
-
Netty的串行无锁化设计体现在哪里
-
Netty解码器中处理TCP粘包、拆包的实现原理以及反序列化处理流程
-
RocketMQ 自定义解码器粘包、拆包处理及反序列化处理流程
RocketMQ 自定义解码器 NettyDecoder 基于 LengthFieldBaseFrameDecoder 实现,根据报文长度提取消息主体。
-
基于 WebSocket 协议的粘包、拆包处理及反序列化处理流程
使用Netty不一定需要自己定义通信协议和实现编解码器,Netty默认支持通过 HTTP协议、WebSocket协议通信,本人接触到的公司项目就是用的 WebSocket 协议。
-
开源框架是怎么用Netty的:
-
RocketMQ
已将 RocketMQ 中通过 Netty 通信的代码抽离到了仓库 SpringBoot-Labs/netty/netty-rocketmq 模块,去除了业务处理,共2K行代码,可以作为模板用在自己的项目中;
实现的功能包括:Reactor主从多线程模型、同步或异步传输、连接空闲超时断线、针对连接的请求信号量限流、断线重连、消息重发,另外还有Socks代理、TLS支持、监控告警(写缓存水位线监控告警)不过这些暂时没有提取出来,还有可以借鉴《Netty权威指南》支持 Protobuf 编解码、HTTP协议、WebSocket协议。
-
Reactor-Netty
基于 Project Reactor 对 Netty 的响应式封装。
源码流程图:
-
Tomcat
之前看过源码但是没有画图时间久了就细节全忘记了,TODO 有空重看下并画下图。
原理简述: 1、创建一个 Acceptor 线程来接收用户连接,接收到之后扔到 events queue 队列里面,默认情况下只有一个线程来接收; 2、创建 Poller 线程,数量 <= 2;Poller 对象是 NIO 的核心,在Poller中,维护了一个 Selector 对象;当 Poller 从队列中取出 Socket 后,注册到该 Selector 中;然后通过遍历 Selector,找出其中可读的 Socket,然后扔到线程池中处理相应请求,这就是典型的NIO多路复用模型。 3、扔到线程池中的 SocketProcessorBase 处理请求。
不过 Tomcat 虽然使用了 NIO 模型,只是优化了请求处理流程中部分操作由阻塞转成了非阻塞,比如 “读请求头”、“等待下一个请求”、“SSL握手”;“读请求体”、“写响应头”、“写响应体”依然是阻塞的(有种说法是需要遵循传统的接口规范以致于无法对所有操作进行非阻塞改写)。
{kind=link}
{kind=link}
-
Spring
-
基于注解的应用上下文
这里主要分析 IOC 和 Spring Bean 生命周期(包括优雅关闭)。
源码流程图:
-
很久之前画的,图有点丑,关于Spring Bean 实例化和初始化流程,参考后面的 spring-beans-factorybean.drawio,更详细。
-
-
切面
-
Spring CgLib and ASM
Spring 代理实现基础,Spring 没有直接引入CgLib和ASM的依赖,而是将它们的部分源码直接迁移到了Spring核心,细节还是挺多的,比较枯燥,流程图省略了很多细节。
-
AOP
关键是生成代理对象,像Spring声明式事务以及Seata数据源代理都注册了一个继承
AbstractAutoProxyCreator的Bean,即代理构造器,其本质是一个BeanPostProcessor,作用是在其他Bean初始化后判断是否需要为Bean生成代理对象,是的话查找所有对应的 Advice、Advisor创建代理对象。参考声明式事务源码分析或者Seata数据源代理源码分析(Seata这部分工作流程图单独提出来了)。
-
-
事务
源码流程图:
-
spring-transaction-5.3.27.drawio (编程式事务源码分析)
-
spring-transaction-5.3.27.drawio.png(编程式事务流程图)
-
spring-transaction.drawio (声明式事务源码分析,sheet2)
不完整(事务处理部分逻辑没画),声明式事务处理实现和编程式有点小区别但差别也不是很大,知道事务操作入口是
TransactionInterceptor就行了,懒得再画一遍了。 -
spring-transaction-declarative.drawio.png (声明式事务流程图)
注意:
如果有两个操作 a(),b(),a() 调用 b(),a() 在事务中执行,b() 方法无论是新建事务执行还是普通执行,如果产生异常没有被捕获,都会被 a() 所在事务捕获到,进而导致 a() 所在事务也回滚。
正确的处理方式:b() 中应该捕获异常,然后通过是否设置 rollbackOnly 标志决定是否让 a() 所在事务也回滚。
事务传播个人认为只是强调多个操作是纳入一个事务管理还是多个事务分开管理,而不是说互不干扰。
初学者容易认为
REQUIRED_NEW新建事务后,即使抛出异常也不会影响之前的事务,这是不对的(对可能存在外部事务的传播类型都做了测试无一例外);原因无论新建事务执行还是普通执行,抛出的异常只要不处理都会最终抛到外部事务中(Spring事务源码发现异常即使捕获也会再次抛出)。 -
-
测试
-
其他
分析IOC时有涉及但是不够详细,所以这里重新绘制单独的流程图。
-
FactoryBean
包括FactoryBean和Bean生命周期的详细分析。
源码流程图:
-
循环依赖处理
源码流程图:
-
Bean创建顺序控制
-
四种依赖注入实现
分析构造器注入、setter方法注入、工厂方法注入(分为静态工厂方法、实例工厂方法 [结合factory-bean使用])。
-
五种不同方式的自动装配
依赖no、byName、byType、constructor、autodetect。
-
-
-
Spring MVC
这里只是分析请求处理流程,Servlet容器初始化流程看Spring Boot的部分(XML配置方式已经不流行了),初始化流程应该也可以参考WebFlux流程图估计差别不大。
源码流程图:
原理简述:
本质是向Servlet容器(比如Tomcat)注册了一个名为
DispatcherServlet的Servlet,通过这个类处理HTTP请求。-
Tomcat 经过一系列处理 Connector -> Processor -> Valve -> Filter链 -> DispatcherServlet,即最终将请求交给
DispatcherServlet处理;在 Spring MVC中注册的过滤器在会添加到Filter链。
-
DispatcherServlet先从请求处理器映射中根据请求方法类型、参数、请求头、请求与响应类型等信息匹配请求处理器; -
然后装配上与请求匹配的拦截器链,生成 HandlerExecutionChain,然后根据请求处理器定义方式获取合适的请求处理适配器,常用的是 RequestMappingHandlerAdapter;
不同的Controller定义方式处理方式不同,现在常用的定义方式是通过 @RequestMapping, 对应的请求处理器适配器是 RequestMappingHandlerAdapter。
-
处理请求前先遍历执行所有匹配的拦截器的 preHandle();
-
通过请求处理器适配器调用请求处理方法,处理流程主要包括:方法参数解析(包括请求消息转换成方法参数类型)、反射调用
Controller业务方法、方法返回数据类型转成响应消息类型,最终通过 HttpResponse 写响应状态、响应主体;
-
遍历执行所有匹配的拦截器的 postHandle();
像 Model View 在前后端分离的项目基本不会使用,暂略。
-
-
Spring Boot
很久之前看源码输出到了Markdown文件,但是内容多了Markdown可读性很差,待补充原理图。
-
Spring WebFlux
源码流程图:
原理简述:
和 SpringMVC 处理流程基本一致,只不过 WebFlux 默认使用 Reactor-Netty 作为Web容器,接口都基于 ProjectReactor 封装成了响应式接口,支持 HTTP 协议 和 自定义协议通信。
与 SpringMVC 的
DispatcherServlet对应有一个DispatcherHandler类,这个类定义了请求处理的主要流程。前面说 Tomcat NIO 模式下请求处理的部分操作依然是阻塞的,只要有操作是阻塞的就会白占线程,降低系统吞吐量,而通过多创建线程提升系统吞吐量则又会引入线程上下文切换的开销。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
响应式编程框架有点类似工具类框架没有主线或者说只有各个接口类实现的独立的主线。
-
源码流程图:
-
这个流程图分析 Mono.delay() 实现原理(可以看作是 Thread.sleep() 的异步非阻塞实现),研究如果实现对阻塞操作的异步非阻塞改造 。
要求:
所有操作都不阻塞,项目中要用响应式,需要将项目中所有组件的阻塞操作都进行异步化改造,这样才能实现更少的线程更大的吞吐量(同时更少的线程也能减少线程上下文切换)。
只要项目中混入了任何阻塞式操作的组件,都会让对应调用链的性能大打折扣,因此使用响应式不是引入Reactor 、WebFlux 这些响应式框架就行了,还需要整个项目生态的组件全部做异步化改造,这也是主要导致 WebFlux 久久无法火起来的原因(其他原因响应式规范不符合人类思维习惯、调试困难[函数式接口、被拆散的流程])。
不过现在JDK21也开始支持虚拟线程了,类似Go协程的概念,从语言层面作出了优化,感觉这东西在后端更难流行起来了。
说所有操作都不阻塞感觉有点不是很严谨,像 Mono.delay() 其实相当于将阻塞操作从本线程中移到了ScheduledThreadPoolExecutor的工作者线程,即工作者线程中为了实现延迟还是有阻塞的,不过多个 Mono.delay() 调用可以复用工作者线程统一处理阻塞操作;有点像 Reactor 模式线程复用的思想。
-
RxJava
{kind=link}
{kind=link}
- Helidon
- Micronaut
- Quarkus
- Spring Cloud
-
Istio
服务都会启动SideCar代理,可以拦截和处理来自其他服务实例的网络流量并提供各种功能,包括负载均衡、故障转移、熔断、限流、安全、监控等等。
-
Apollo
-
Nacos
源码流程图:
- Zookeeper
-
源码流程图:
-
很久之前画的没有UML,而且图太过罗嗦,TODO 重画。
-
-
Curator
-
分布式锁 InterProcessMutex
TODO。
-
-
-
源码流程图:
业务使用:
-
源码流程图:
-
Hystrix
{kind=link}
{kind=link}
{kind=link}
-
Skywalking
-
Agent
源码流程图:
-
-
Sleuth
-
OpenTelemetry
{kind=link}
-
Prometheus
暂只关注数据采集和上报的原理,业务定制也主要是这部分。
-
client_java
感觉和 Skywalking Agent 库的代码组织有点像也有一堆根据服务实例中各种组件定制的数据采集组件,可以按需引入。
源码流程图:
拓展:
-
micrometer-registry-prometheus
Micrometer 适配 Prometheus上报接口的数据采集器组件,代码感觉有点乱,还有一堆函数式编程,代码可读性较差。
源码流程图:
-
{kind=link}
{kind=link}
-
Apache Shiro
-
pac4j
-
Sa-Token
参考后面分析的 Sa-Token OAuth2 工作流程。
-
-
主流程
源码流程图:
-
-
JCasbin
JCasbin 提供了简单易用、灵活、强大的权限校验模型,可以替换 Spring Security、Shiro 中的权限校验模块。
源码流程图:
-
认证协议
系统多个服务(包括外部服务)整合统一的认证授权服务时会用到,使用最多的是 OIDC 和 OAuth2。
-
OAuth2
包括四种角色(资源所有者、客户端[APP、Web服务等等]、认证服务器、资源服务器,认证服务器和资源服务器可以是一个服务)、四种模式,认证服务器包含一组固定的HTTP接口处理客户端的认证请求。
不只是可以用在第三方授权,企业内部系统也是可以的,还可以用于实现单点登录,之前公司内部系统就是用 OAuth2 对接 GitLab、YAPI、Kibana、自己的管理后台、监控后台等等服务。
学习 OAuth2 工作原理和细节看再多的资料不如看一遍源码理解的清晰,推荐看 Sa-Token 的源码比较简单,一天即可看完主流程实现包括内部细节。
-
Spring Security OAuth2
源码流程图:
-
Sa-Token OAuth2
源码流程图:
-
-
OIDC (OpenId Connect)
从 Sa-Token 的源码实现看就是基于 OAuth2 认证流程、使用 JWT 形式包装用户信息;看文档定义(OIDC 是什么)的话可能感觉OIDC不好理解,但是从源码上理解其实超级简单,以SaToken为例,OAuth2 和 OIDC 就是 UserIdScopeHandler 和 OidcScopeHandler 这两个类的区别。
-
SAML
-
CAS
-
JWT
比较简单不详述了。
-
{kind=link}
{kind=link}
{kind=link}
-
Mybatis
-
主流程
源码流程图:
也是好久之前画的图,UML不详细,导致回看不好理解,SQL前后置处理以及连接池部分还有细节逻辑没有梳理,TODO 重画。
-
重要组件分析:
-
mybatis-cache.drawio (Mybatis 两级缓存工作原理)
-
- 两个事务中同时执行同一条查询语句使用二级缓存是怎么保证不会出现脏读的
- 二级缓存联表查询数据不一致问题产生的原因
- SpringBoot 集成 Mybatis 非事务方式连续两次执行同一条查询,为何第二次不会命中一级缓存
综上:SpringBoot Mybatis 项目默认配置下其实根本不会用到 Mybatis的缓存。
-
mybatis-plugin.drawio (Mybatis 插件工作原理)
-
插件原理:通过 JDK 动态代理将插件通过 Interceptor 接口定义的拓展逻辑封装到 Mybatis SQL执行组件中,可以 拦截 Exuecutor StatementHandler ParameterHandler ResultSetHandler 的方法,对SQL语句、参数、返回值进行额外处理;
这里以 PageHelper 为例分析插件的XML配置解析、实例化、初始化、注册原理,插件都可以增强数据库访问中哪些过程和组件(Executor、StatementHandler、ParamterHandler、ResultSetHandler),以及插件增强原理(JDK动态代理层层封装)。
由于 PageHelper 分页基于 LIMIT ?, ? 实现,这种分页方式有深度分页问题,只适合小数据量的表,所以 PageHelper 平时使用的并不多。
-
-
Mybatis-Spring
-
-
Mybatis Plus
{kind=link}
{kind=link}
{kind=link}
-
Canal
之前梳理了个半成品,TODO 重画。
-
DataX
数据库迁移工具,阿里云DataWorks的开源版本。
-
Redis
Redis的源码看起来并不难理解,平时使用基本用不着看源码;只在需要理解某些重要问题(比如某个命令是否有性能问题)底层原理时看对应部分源码就行了(也可以看《Redis源码剖析与实战》了解大概流程,碰到具体问题能快速找到对应处理代码即可)。
源码流程图(6.2.6):
-
redis-client-server.drawio (Redis Client/Server 流程,sheet1: 客户端、sheet2: 服务端)
-
redis-server.drawio.png (服务端对请求处理流程)
这里主要关注 Redis Server 基于 epoll IO多路复用模型对请求的处理流程,以及 Redis 命令解析分发和执行流程(需要知道客户端输入一个命令,命令最终是由 Server 中哪个方法执行的)。
最好先参考《Linux系统编程》等书籍回顾下 epoll 是怎么使用的,不然可能看不懂上面的流程图;或者参考这个 epoll 示例:epoll_server.c 。
-
-
redis-cmd-set.drawio (Redis Server set命令处理流程)
-
redis-cmd-rpush.drawio (Redis Server rpush命令处理流程)
-
redis-cmd-zadd.drawio (Redis Server zadd命令处理流程)
-
redis-inner-ds.drawio (Redis Server 内部基础数据结构)
-
obj_encoding_skiplist2.png (跳表的数据结构)
发现技术圈很喜欢讨论跳表,这里单独列出来之前画的一张ZSet跳表的结构图以及参考Redis源码使用Java重新实现的跳表ZSkipList.java,此跳表实现原理说明参考 redis-data-structure.md 。
-
-
redis-pubsub (Redis发布订阅)
后面 Redisson 发布订阅源码分析中仅仅是展示Redisson对发布订阅的封装,不包含Redis服务端内部对发布订阅的实现。
TODO: Redis发布订阅命令源码流程图补充。
-
redis-stream (Redis Stream)
TODO: 源码流程图补充。
-
redis-transaction (Redis事务)
Redis事务其实说的只是并发的原子性,保证事务中的多个命令执行时中间不会插入其他客户端的命令。没有事务控制时为何可能插入其他客户端的命令?看上面IO多路复用模型就明白了:多个客户端同时发送命令,先获取到哪个客户端的命令就绪事件无法确定,所以高并发场景下一个客户端先后发送两个命令,中间很可能插入其他客户端的命令; 要实现Redis事务其实就是要么将多个命令合并成一个命令一起发送;要么就是先缓存到服务端的队列,当提交EXEC后,再将这批命令一起取出来一起执行;根据一些资料看实现原理是第二种方案。
TODO: 源码流程图补充。
-
定期删除任务由
bio_lazy_free线程执行,但是此线程只是负责扫描过期key并加入异步队列,过期的key最终是还是由时间事件循环交由主线程执行删除命令进行删除,所以定期删除扫描任务中的思想是少量多次有间隔地删除,而不是扫描全部的过期key一起删除以防止阻塞客户端命令的执行。如果有一批key同时过期,定期删除策略也只能缓解对其他key读写效率的影响。
重要问题分析:
-
Redis 6.0 开始到底哪里支持了多线程
看上面 redis-server.drawio.png 会发现没有用到多线程啊?这是因为IO多线程默认是关闭的需要修改服务端配置(redis.conf),然后
redis-server redis.conf启动,启动后ps -T -p <pid>可以看到多线程模式相对于单线程模式多出来几个线程io_thd_<n>,暂时没时间看这部分源码,可以先参考Redis 6.0的多线程 这篇文章,后面会添加流程图(TODO)。# 开启网络IO多线程 io-threads-do-reads yes # 设置IO线程数量为8 io-threads 8 # 查看 redis-server 进程下的所有线程,上面io-threads 8 包括main线程 ~ ps -T -p 96007 PID SPID TTY TIME CMD 96007 96007 pts/4 00:00:00 redis-server # 主线程,即处理客户端命令的线程 96007 96028 pts/4 00:00:00 bio_close_file 96007 96029 pts/4 00:00:00 bio_aof_fsync 96007 96030 pts/4 00:00:00 bio_lazy_free # 这个线程是过期key定期删除的扫描线程 96007 96031 pts/4 00:00:00 io_thd_1 96007 96032 pts/4 00:00:00 io_thd_2 96007 96033 pts/4 00:00:00 io_thd_3 96007 96034 pts/4 00:00:00 io_thd_4 96007 96035 pts/4 00:00:00 io_thd_5 96007 96036 pts/4 00:00:00 io_thd_6 96007 96037 pts/4 00:00:00 io_thd_7
-
Redis ZSet 中最多只存储20W热点数据,每次新增热点数据时使用 zcard 查看数量,超过 20W 使用 zremrangeByRank 删除最早添加的数据,这个数据量 zcard zremrangeByRank 有没有性能问题
这两个命令肯定没有性能问题,插入操作和检索操作需要评估下,这数据量一定是跳表,使用跳表读写时间复杂度是 O(Log(N)),20W 数据属于大key,一般规定 Set 类型不要超过1W数据,20W数据量相对于 1W 数据估计大概多5次循环,内存中5次循环还是可以接受的,不过建议还是做拆分,比如按地域、按用户尾号拆分到不同的key中,主要是避免大key导致在集群中出现数据倾斜。
-
-
Sharding-JDBC
TODO 流程图迁移。
-
连接池
这些连接池可以对比着看源码,比较下各自优缺点。
-
Mybatis PooledDataSource
-
Druid
-
HikariCP
-
{kind=link}
{kind=link}
-
Atomikos
-
ByteTCC
-
EasyTransaction
-
Hmily
源码流程图:
-
hmily-producer-consumer.drawio.png
Hmily 基于 Disruptor 实现的事件发布订阅(生产者消费者模式)。
-
LCN
-
RocketMQ事务消息
参考 RocketMQ 部分。
-
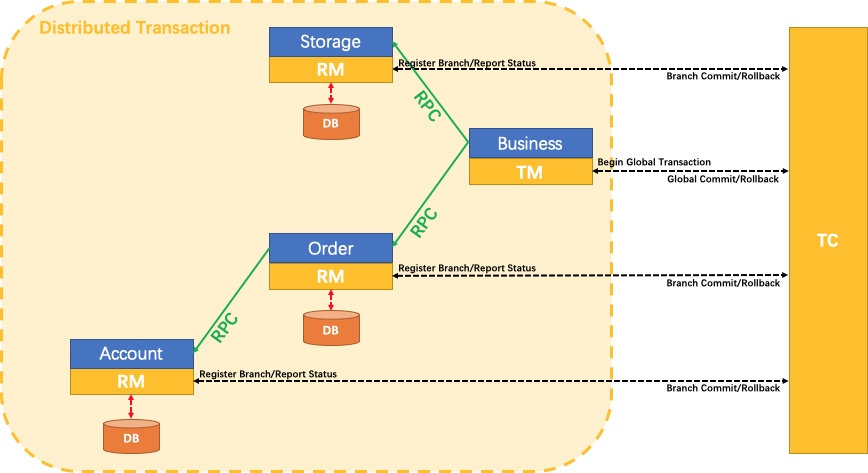
Seata
包含一套分布式事务方案适用于不同要求的一致性场景,总代码量很大,但是核心代码量没有那么吓人,只需要关注seata-server、seata-core、一种配置中心的支持(如seata-config-nacos)、一种服务发现的支持(如seata-discovery-nacos)、一种通信方式支持(如 RestTemplate、Feign、GRPC、Dubbo)、三大组件(RM TM TC)、各种事务实现模式(AT、TCC、Saga、XA)。
源码流程图:
-
seata-server.drawio (Seata服务器,作为TC)
-
这里主要分析 AT 模式。TC 、TM 、RM 组件之间通过 Netty 通信,Netty 通信端口默认是 HTTP 通信端口 + 1000,Netty 通信组件封装和 RocketMQ 中 Netty 组件的封装大致相同。
-
seata-client.drawio (Seata客户端,作为TM 和 RM)
-
这里主要分析 AT 模式。每个客户端启动时都会启动 TM RM 的 Netty 客户端,但是只有全局事务发起者才会使用 TM 客户端,如果一个服务仅仅作为事务参与者只会用到 RM 客户端。
-
seata-at-overview.drawio (Seata AT模式流程概图)
-
感觉官方文档中原理图太过简略了,无法体现很多重要信息,重新绘制了AT模式工作原理概图。
AT模式也是基于业务补偿的两阶段提交;业务补偿方面类似TCC,但是AT模式可以自行生成用于补偿的 UndoLog,而不是像 TCC 模式需要手动编码实现补偿逻辑,也即没有业务侵入;AT模式的两阶段提交,第一阶段:实现各分支事务的注册、执行、提交(注意第一阶段分支事务就会提交),第二阶段:如果是提交的话其实主要是执行事务数据的清理,比如删除 UndoLog(可以异步执行),如果是回滚的话,主要是查询各分支事务 UndoLog 并执行进行补偿。
-
seata-datasourceproxy.drawio (数据源代理 DataSourceProxy)
-
seata-datasourceproxy.drawio.png
Seata @GlobalTransactional 增强的逻辑中并不包含事务操作,事务操作是通过 DataSourceProxy 实现,分支事务执行可能会同时经过 @Transactional 和 DataSourceProxy 事务操作,但是两者并不冲突,DataSourceProxy 中会先判断当前是否已经开启事务,如果已经开启不会重复开启。
DataSourceProxy 本身不是基于 Spring AOP 实现,调用数据源接口时切换到 DataSourceProxy 的流程是基于 Spring AOP 实现的,详细参考
SeataAutoDataSourceProxyCreator流程,它继承AbstractAutoProxyCreator,本质是一个BeanPostProcessor。DataSourceProxy 通过装饰器模式对数据源操作扩展事务处理逻辑,比如通过 ConnectionProxy 为连接操作拓展事务处理包括向TC注册分支事务信息、记录UndoLog等等。
-
seata-at-globallock.drawio.png
Seata 全局锁用于保证不同分布式事务的写隔离和读隔离,本质就是通过一组分布式行锁保证同步执行(排队),详细参考:seata-at-globallock.md。
全局锁在 TC 中实现,实现原理其实很简单就是基于主键唯一索引进行插入,插入成功获取锁成功,插入失败获取锁失败,和Redis set nx 原理一样。
@GlobalLock用在不需要全局事务而又需要检查全局锁避免脏读脏写的场景(比如某个纯粹的本地事务查询全局事务可能会修改的某行数据,这种场景应该还是挺常见的),这种场景使用@GlobalLock注解更加轻量。这里纯粹的本地事务指不属于任何全局事务的本地事务。
-
seata-configurationfactory.drawio.png
Seata 支持多种注册中心、配置中心的适配器实现;
这种适配功能很常用,初学者不清楚怎么实现可以参考下,其实很简单就是定义一组通用接口方法,使用各个不同的注册中心、配置中心重新实现这些接口。
关键问题分析(部分节选自官方FAQ):
-
@GlobalTransactional 注释的方法明明没有像 @Transactional 拓展事务操作为何这个方法中执行的SQL还是可以在出现异常后被回滚
-
注意 TransactionPropagationInterceptor 中的事务传播只是说 XID 的传递,和 Spring 事务传播不是一个概念。
-
怎么使用Seata框架来保证事务的隔离性
即上面的全局锁。
-
脏数据回滚失败如何处理
结合告警、 UndoLog 手动处理。
-
抛出异常后事务未回滚
官方文档直接列举了一些可能原因,但是感觉这种回答方式不太好,应该结合抛出异常到事务回滚的流程一步步排查,清楚内部流程的话应该怎么排查很清楚。
-
-
TCC-Transaction
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- ElasticSearch
- Drools
- Activiti
- Spring Flowable
-
Caffeine
-
Ehcache
TODO。
-
一致性协议
-
说实话想自己按 Raft 论文写一个实现也不是个简单的事,关键是需要将论文中的所有细节理解清楚,里面有一些证明能否理解透彻,即便写出来,怎么测试实现的没有漏洞也是个问题。
-
BRaft
Raft协议的C++实现。
-
JRaft
看 Nacos 当前最新版本(2.3.2)中依赖的是 SOFAJRaft,简称JRaft,是参考 BRaft 的 Java 实现。
可以参考 Seata RaftServer 了解如何使用 JRaft 实现一个分布式一致性文件系统。
-
Raft4J
-
Raft-Java
这个只是DEMO性质的实现,主要是代码实现简单(5K多行,其他生产级别的实现都是几W行),适合快速学习Raft协议细节。
源码流程图:
-
-
{kind=link}
- JCommander
- CLI
-
Slf4j
-
Log4j2
-
Logback
虽然 logback-core、logback-classic 代码量加起来有 6W 行,但是核心流程比较简单,且数据结构很清晰,直接看源码可能比看官方文档和书能更快地理解 Logback 的工作原理和使用细节。
源码流程图:
{kind=link}
-
Fastjson
基于FastJson2源码分析,从源码实现上看主体逻辑其实比较简单,之所以源码代码量很高更多地是因为编程语言语法的复杂性(需要适配各种各样的类型和语法,而且要用ASM定义ObectWriter动态类,调试时可以发现有很多if判断,还有一些对特定类型的定制实现,但是实际的类型可能只会用到其中少部分处理逻辑)。
序列化主体逻辑可以分为3部分(以 ObjectWriterCreatorASM 为例): 1)通过Class解析一个类型需要序列化的部分(比如公共基本类型字段、有实现 Getter 方法的私有基本类型字段、对象类型字段、继承的字段等等),针对每个字段会创建一个 FieldWriter 实现对这个字段的序列化;
2)为此类型通过 ASM 字节码动态生成一个专属的 ObjectWriter 类进而加载并实例化,用于专门实现对这个类型对象的序列化写操作,通过这种方式避免了反射的低效性,而且 Fastjson 会缓存这些动态生成的 ObjectWriter 类,后续再序列化会很快;
3)使用 ObjectWriter 对每个字段进行序列化并追加到最终的序列化结果。
源码流程图:
-
Hessian
-
Jackson
TODO。
-
Kryo
-
Protostuff
{kind=link}
-
Arthas
-
EasyExcel
-
Guava
-
Hutool
-
JETCD
-
分布式锁
对比Redisson实现(TODO)。
-
-
jvm-sandbox
TODO 流程图迁移
-
MapStruct
-
Redisson
-
发布订阅
这里分析Redisson Netty连接管理、通信管道和发布订阅流程。
源码流程图:
-
源码流程图:
-
-
redisson-lock-RedissonLock.drawio.png
多数锁继承 RedissonLock,梳理清 RedissonLock 再看其他锁的实现会简单很多,可以看到Lua脚本才是核心; 包括加锁解锁流程以及看门狗实现原理。
-
注意:
红锁(RedLock)在新版本已经废弃。
-
-
分布式延迟队列
-
RDelayedQueue (TODO)
基于ZSet数据结构实现,延迟时间作为分值,定时任务扫描,取出到期的延迟消息给业务线程处理。 扫描延迟消息的定时任务可以用计划任务线程池或Timer实现(看其他框架实现时见到好多次了),Redisson 用的哪种后面有空再看。
-
-
Future、Promise模式
源码流程图:
-
-
AsyncSemaphore
借助 CompletableFuture 实现的异步非阻塞的 Semaphore,设计也挺巧妙的仅仅用了80行代码就实现了一个异步非阻塞的信号量。不过注意这个不是分布式的信号量,分布式信号量还是需要使用 RedissonSemaphore。
源码流程图:
-
-
-
基于 DFA (Deterministic Finite Automaton,确定有穷自动机)算法的敏感词工具(基于前缀树数据结构,此工具借助 HashMap 存储下一级字符节点),支持很多细节控制(比如格式转换、全角半角、大小写、邮箱检测、网址检测、白名单等等)。
有些关于DFA算法的介绍(参考维基百科确定有限状态自动机)还有什么事件、状态转换,但是从一些实现看并没有涉及这些东西,感觉是概念将问题描述的复杂化了,实现其实很简单。
源码流程图:
-
源码量不高,作者加了很多注释,代码很容易理解,这里不详细画流程图了,只看数据结构的 UML就能推导出逻辑 。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-
Antlr
Sharding-JDBC 中 借助 Antlr 实现对 SQL 语句的重构(原SQL -> AST -> 新SQL),将 SQL 转换成针对某个分表的 SQL。
- Consul
- Etcd
-
Istio
-
K8S
- DTM
- Tokio
-
音乐
-
网易云音乐 Linux 版已经不支持下载了,而且网上版本很老,然后发现了这个项目,基于 GTK + 网易云音乐API 实现。
TODO:可以研究下源码(当前2.5.0版本,代码量大概8K行),打包自用,也可以了解下 Rust + GTK Linux 桌面程序开发和打包。
-
读框架源码的初衷:
-
解决生产环境BUG
不熟悉源码原理,可能即使定位到问题所在代码行也不知道是什么原因应该怎么改。
-
从0到1构建项目时,定位导致产生不符合预期结果的原因
这个碰到太多了,通过Google、官方文档可以解决大部分,但还是有一些无法查到的问题。
-
拓展框架功能(很多框架都有预留一些扩展点)
拓展方式比如扩展钩子、SPI、插件、JVMTI Agent什么的。
-
更好更合理地使用技术和框架
通过源码可以更透彻地理解某个技术的实现原理和细节,因为文档很难描述某些代码逻辑,也很难透漏所有细节,这也导致有些文档难以理解,甚至根据文档理解的是片面的或错误的。
几乎所有框架的文档都没法将框架所有功能的细节都讲解清楚,熟悉原理可以帮助开发时避坑。
-
满足对框架内部工作原理的好奇心,也便于后期出现BUG排查BUG
-
借鉴方案设计
对一陌生的场景进行方案设计时,一定要先多参考已有的设计,梳理设计要点,比较不同方案的优缺点,不要闭门造车,否则很容易设计出存在很多漏洞的方案;
-
学习代码架构设计、代码风格规范、对依赖框架的封装和使用、提取轮子等
-
以不变应万变
对框架源码有清晰认识之后,很多问题没必要死记硬背(不是天天用肯定会忘),用到再看下对应模块源码即可,有什么坑怎么解决源码会告诉我们一切。
做企业级的方案设计的时候,如果不是对业务很熟悉(熟知需要关注哪些点、会存在什么坑);首先需要多参考开源的方案设计,对比优缺点,总结都需要注意哪些坑,在此基础上再设计符合自己业务的方案。
对读框架源码的心得:
-
读源码需要画图辅助记忆和理解
这一点是最关键的,解决看源码看了后面的逻辑忘了前面的逻辑的问题(面向生产的框架代码量一般都比较大,应该没有人看了成千上万行代码后对前面的流程细节还记得清清楚楚的吧),这个问题是制约我刚开始学后端迟迟无法深入源码的主要问题。
曾经为了解决这个问题,试着写过源码分析文档(Markdown,写的多了回顾发现和重新看源码一样无法立刻回想起这段代码的作用和其他模块的关系)、画过思维导图、流程图(流程复杂了看着很乱)、时序图(绘制复杂且空间利用率低,即不方便看)但是效果都不好,最后突然想到为何不按时序图的编排方式画流程图,即使流程复杂也不会乱且格式较时序图更紧凑且方便绘制,后来因为流程图只能体现”算法“逻辑无法体现”数据结构“,又添加进去了简化的UML图,最终形成了现在的流程图。
通过现在的流程图,可以快速回顾框架的主流程以及架构。
-
大部分框架源码是复杂但不是难,只是梳理过程比较费时间
研究清楚某个逻辑的完整实现流程,可能会涉及几十个源码文件,很多层调用。
-
大部分框架都有一个主流程逻辑,主流程逻辑占全体代码量一般并不高,也是主要要看的;除了一些工具类框架,比如
Hutool、Redisson没有主流程面向生产的框架,里面很多功能点,一般都会为功能点提供较全的实现方案,它们的接口和功能类似,通常只需要梳理一种方案实现即可。
比如框架中常见的配置解析,可能支持Properties 、Json、Yaml、Toml等配置方式;又比如通信框架中可能支持TCP UDP HTTP WebSocket等各种协议实现,梳理主流程时只需要关注其中一种实现。
-
需要清楚代码阅读边界
框架里面可能依赖其他框架,不熟悉被依赖的框架,不要立即跳转进去看源码,先通过被依赖框架官方文档了解接口功能即可,以当前框架为主。
-
很多框架在代码架构上有用一些相同的架构思想、设计模式、技术实现方法
多总结这些内容,可以加速对新框架源码的理解。
-
想了解某一部分源码的逻辑可以结合相应的单元测试代码调试
-
检验对源码的熟悉度可以通过尝试从中提取Mini版的框架
-
读源码时组件初始化代码可以先不看细节,在分析流程逻辑时用到再回来找
文档规范:
后面新 Markdown 文档统一使用 4W2H 规则编写。
4W2H:What (是什么)、When/Where(什么时候使用或者用在哪里)、Why(为什么选择这个)、How(怎么实现的)、How(怎么使用), 即 介绍(包括功能)、场景、优劣、原理、应用。
有电子版的书基本上在 ZLibrary 都能找到。