Flattening
SCALPEL-Flattening is a library part of the SCALPEL3 framework. This library, based on Apache Spark, denormalizes Système National des Données de Santé (SNDS) data to accelerate concept extraction when using SCALPEL-Extraction.
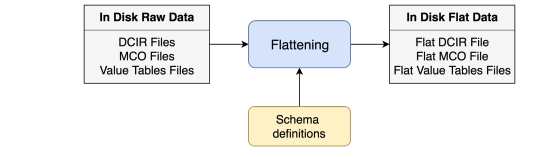
SCALPEL-Flattening denormalizes the data “once and for all” to avoid joining many tables each time the data of a patient is accessed. Its input is a set of CSV files extracted from the original SNDS database, which is provided by CNAM
SCALPEL-Flattening consists of two main processes: Convert and Join. We can run both of 2 processes together or one of them on demand.
- Convert: applies the CNAM data-schema to the input CSV files, checking their consistency with the data, performing eventual type conversions(this conversion can be found in data-schema) and finally processing columns formats if necessary (for example addMoleculeCombinationColumn in IR_PHA_R)
- Join: performs the joins the many input tables to produce a single big table per database. The joins are performed over by time slices(by year or by month) to ensure the scalability of this process. When all the slices are joined, they are concatenated to result in the desired flat table. The size of the time slice can be configured.
After Convert and Join, the data will be saved in Parquet or ORC defined in configuration and Only the table in data-schema can be extracted.
The following table shows the possible monthly partition column used in join process.
| Flat Table | Monthly Partition Column |
|---|---|
| DCIR | FLX_DIS_DTD, EXE_SOI_DTD |
| PMSI_MCO | EXE_SOI_DTD |
| PMSI_MCOCE | EXE_SOI_DTD |
We do not recommend to join tables by month, because performing data manipulation on SNDS requires more joins and can consequently be extremely slow.
The following table describes all the concepts available in SCALPEL-Flattening.
| Table Name | Description | Table Composition |
|---|---|---|
| Single Table | Raw data issued by Caisse Nationale d'Assurance Maladie (CNAM) (the data producer and maintainer), from their SQL databases, in CSV format, and accumulated year by year. Each CSV file representing a table. SCALPEL-Flattening converts such tables to Apache Parquet files, that is single table | ER_PRS_F, ER_PHA_F, ER_CAM_F, ER_ETE_F, ER_UCD_F MCO_C, MCO_A, MCO_B, MCO_D, MCO_UM MCO_CSTC, MCO_FMSTC, MCO_FASTC HAD_A, HAD_B, HAD_C, HAD_D, HAD_MED, HAD_MEDATU SSR_C, SSR_B, SSR_CCAM, SSR_D, SSR_CSARR, SSR_MED, SSR_MEDATU SSR_FASTC, SSR_CSTC, SSR_FBSTC, SSR_FCSTC, SSR_FMSTC |
| Flat Table | The flattening joins a group of single tables to produce a final table(flat table) for each of them, and then save it as Parquet files | ER_PRS_F, ER_PHA_F, ER_CAM_F, ER_ETE_F, ER_UCD_F =>DCIR MCO_C, MCO_A, MCO_B, MCO_D, MCO_UM =>PMSI_MCO MCO_CSTC, MCO_FMSTC, MCO_FASTC=>PMSI_MCOCE HAD_A, HAD_B, HAD_C, HAD_D, HAD_MED, HAD_MEDATU=>HAD SSR_C, SSR_B, SSR_CCAM, SSR_D, SSR_CSARR, SSR_MED, SSR_MEDATU=>SSR SSR_FASTC, SSR_CSTC, SSR_FBSTC, SSR_FCSTC, SSR_FMSTC=>SSR_CE |
| Reference Table | such as IR_PHA_R, IR_BEN_R, IR_IMB_R, containing code mappings (for drugs, acts, diagnoses, etc) are not like other single tables accumulated year by year and are not forced to be included in the flattening for now | IR_PHA_R, IR_BEN_R, IR_IMB_R |
Flattening produces a metadata file in the JSON format that contains the paths of data output. That JSON will be used as input in the Flattening Stats API
{
"class_name" : spark job name,
"start_timestamp" : start_timestamp,
"end_timestamp" : end_timestamp,
"operations" : [ {
"output_table" : table name,
"output_path" : output path,
"output_type" : "single_table|flat_table",
"sources" : list of input paths
"join_keys" : list of join keys
}
...
]
}