
W3C Xpath 1.0 표준 구문을 지원하는 순수 Java로 구현된 HTML 파서입니다. Jsoup과 Antlr4를 기반으로 xpath를 사용하여 HTML 데이터를 파싱 및 추출하는 파서입니다. Java에서 가장 우수할 수 있습니다. 반드시 시도해보세요.
JsoupXpath는 HTML 데이터를 xpath를 사용하여 파싱 및 추출하기 위한 순수 Java로 개발된 파서입니다. HTML 파싱을 위해 W3C XPATH 1.0 표준 구문을 완전히 재구현하였으며, xpath의Lexer와 Parser는 Antlr4를 기반으로 구축되었으며, HTML의 DOM 트리는 Jsoup을 사용하여 생성되었습니다. 따라서 이 이름이 JsoupXpath입니다. Java에서 xpath의 강력함과 편리함을 즐기고 싶지만 충분히 사용하기 좋은 xpath 파서를 찾기 어려웠기 때문에 JsoupXpath를 개발하였습니다. JsoupXpath의 구현 로직은 명확하고 확장이 용이하며, W3C XPATH 1.0 표준 구문을 완전히 지원합니다. W3C 표준: http://www.w3.org/TR/1999/REC-xpath-19991116, JsoupXpath 구문 설명 파일 Xpath.g4
https://github.com/zhegexiaohuozi/JsoupXpath/releases
- 문제
https://github.com/zhegexiaohuozi/JsoupXpath/issues
- 위챗 구독 계정

여기에서는 사용 사례와 같은 글들을 게시하며, seimi 체계 관련 프로젝트의 최신 업데이트 동향 등도 공유됩니다. 또한, 저자의 인터넷 백엔드 기술에 대한 글과 느낀 점 등도 게재됩니다.
maven 의존성, 전체 버전은 릴리스 정보 또는 중앙 maven 저장소를 참조하세요:
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
예시:
String html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>";
JXDocument underTest = JXDocument.create(html);
String xpath = "//div[contains(@class,'xiao')]/text()";
JXNode node = underTest.selNOne(xpath);
Assert.assertEquals("Two",node.asString());
기타 참고ntp: org.seimicrawler.xpath.JXDocumentTest,여기에는 많은 테스트 케이스가 있습니다.
또는 Issue에서 전형적인 예제를 참조할 수 있습니다.
완전한 W3C XPATH 1.0 표준 문법을 지원합니다. W3C 사양: http://www.w3.org/TR/1999/REC-xpath-19991116
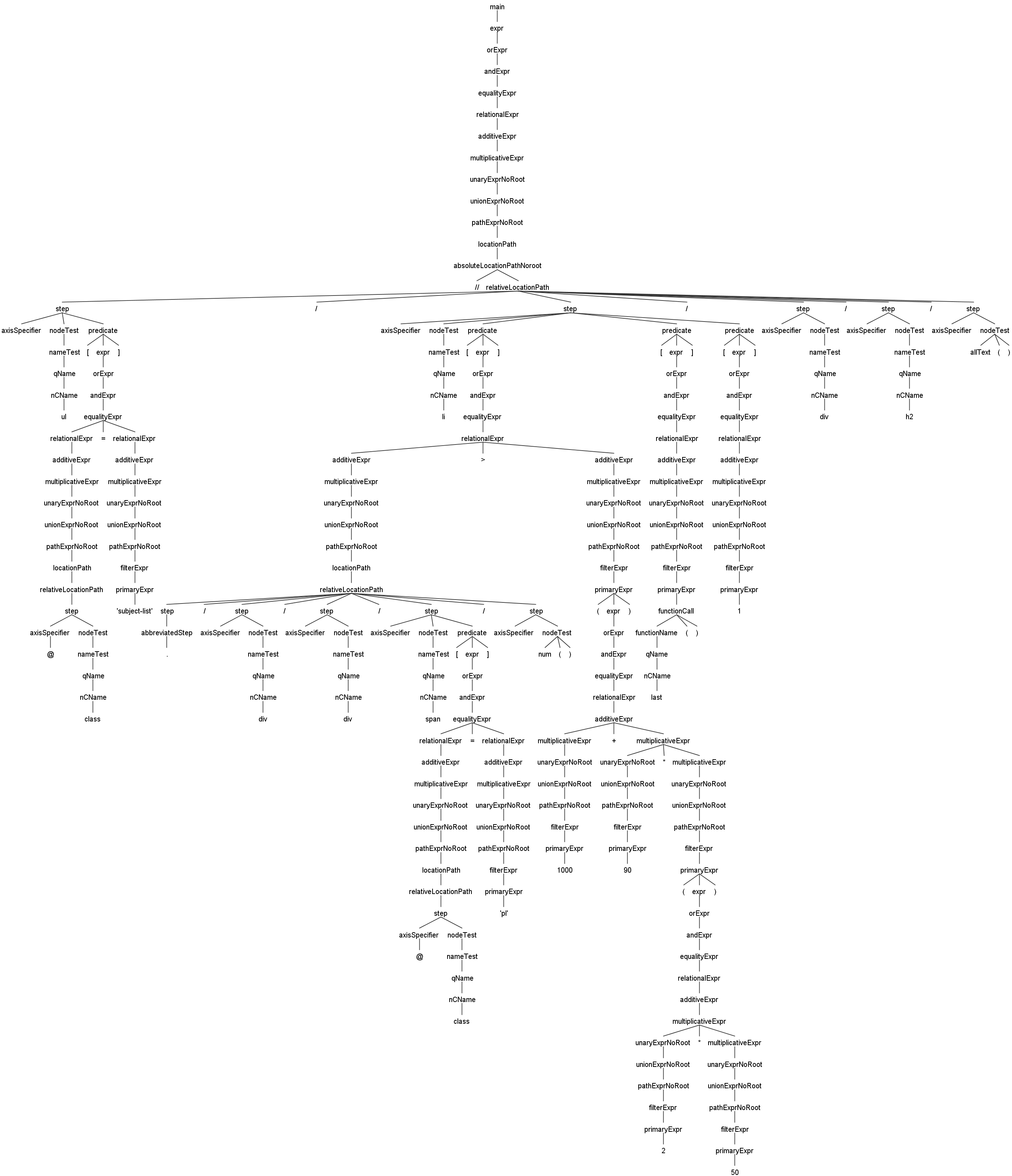
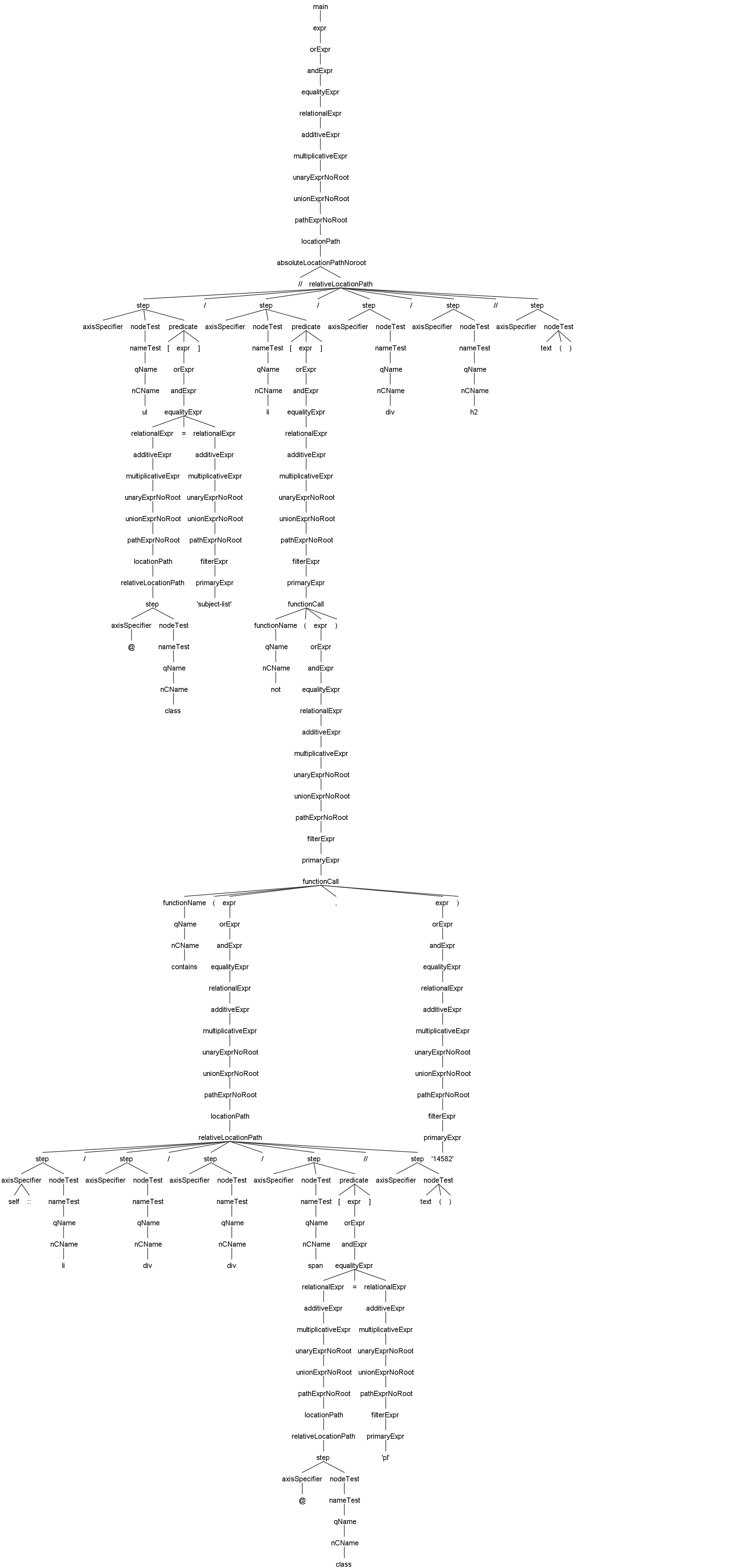
여기는 JsoupXpath의 Antlr4 기반 문법 분석 트리 예시입니다. 이를 통해 JsoupXpath의 문법 처리 능력과 문법 분석 실행 과정을 더 빠르게 파악할 수 있습니다.
-
//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()이는 주로 일부 표현식 중첩의 분석 예시입니다. 이미지를 클릭하면 큰 이미지를 볼 수 있습니다. -
//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()이는 내장 함수 지원에 대한 분석 예시입니다. 이미지를 클릭하면 큰 이미지를 볼 수 있습니다.
다수의 경우 Firefox 또는 Chrome에서 생성된 Xpath를 직접 복사해서 사용하는 것은 권장하지 않습니다. 이러한 브라우저는 페이지를 렌더링할 때 자동으로 일부 태그를 표준에 따라 보완합니다. 예를 들어, table 태그는 자동으로 tbody 태그가 추가됩니다. 이렇게 생성된 Xpath 경로는 가장 일반적이지 않을 수 있으므로 값이 제대로 가져와지지 않을 가능성이 있습니다. 따라서 Xpath를 사용하고 Xpath의 강력함과 편리함, 우아함을 경험하려면 Xpath의 표준 문법을 배우는 것이 가장 좋습니다. 이렇게 하면 다양한 문제를 쉽게 해결하고 Xpath의 진정한 힘을 즐길 수 있습니다!
-
int position()현재 노드가 해당 컨텍스트에서의 위치를 반환 -
int last()해당 컨텍스트에서의 마지막 노드 위치를 반환 -
int first()해당 컨텍스트에서의 첫 번째 노드 위치를 반환 -
string concat(string, string, string*)여러 문자열을 연결 -
boolean contains(string, string)첫 번째 문자열이 두 번째 문자열을 포함하는지 판단 -
int count(node-set)주어진 노드 세트의 노드 개수를 계산 -
double/long sum(node-set)주어진 노드 세트의 숫자 노드 값의 합을 계산, 계산 범위 내에 비숫자 내용이 포함되면 계산이 무효 -
boolean starts-with(string, string)첫 번째 문자열이 두 번째 문자열로 시작하는지 판단 -
int string-length(string?)문자열이 주어지면 문자열 길이를 반환, 주어지지 않으면 현재 노드를 문자열로 변환하여 길이 반환 -
string substring(string, number, number?)첫 번째 매개변수는 문자열, 두 번째는 시작 위치(xpath 인덱스는 1부터 시작), 세 번째는 추출할 길이를 지정, xpath 문법에서 이는 종료 위치가 아니라 주의해야 함.substring("12345", 1.5, 2.6) returns "234"
substring("12345", 2, 3) returns "234"
-
string substring-ex(string, number, number)첫 번째 매개변수는 문자열, 두 번째는 시작 위치(java 습관에 따라 0부터 시작), 세 번째는 종료 위치(부호를 지원), 이는 JsoupXpath 확장 함수로 java 사용자에게 편리함. -
string substring-after(string, string)첫 번째 문자열에서 두 번째 문자열 다음 부분을 추출 -
string substring-after-last(string, string)첫 번째 문자열에서 두 번째 문자열의 마지막 출현 위치 다음 부분을 추출 -
string substring-before(string, string)첫 번째 문자열에서 두 번째 문자열 이전 부분을 추출 -
string substring-before-last(string, string)첫 번째 문자열에서 두 번째 문자열의 마지막 출현 위치 이전 부분을 추출 -
date format-date(string, string ,string)첫 번째 매개변수는 표현식, 두 번째는 표현식 값의 시간 형식, 세 번째는 시간대 로케일, 선택 사항
이상은 XPath 1.0 표준의 함수들입니다. 개발자는 org.seimicrawler.xpath.core.Function.java 인터페이스를 구현하고 시스템 초기화 시 Scanner.registerFunction(Class<? extends Function> func)를 호출하여 사용자 정의 함수를 쉽게 추가할 수 있습니다. 구문 패러다임을 수정할 필요 없이, JsoupXpath는 실행 시 인식하여 로드합니다. 현재 JsoupXpath에서 구현되지 않은 표준 구문의 함수는 메인 저장소에 Pull request를 제출하여 함께 개발에 참여할 것을 환영합니다.
allText()노드 하위의 전체 텍스트를 추출,//div/h3//text()와 같은 재귀적 텍스트 추출 용법 대체html()전체 노드의 내부 HTML을 가져옴outerHtml()전체 노드를 포함하여 노드 자체를 포함한 전체 HTML을 가져옴num()노드의 자체 텍스트에서 모든 숫자를 추출, 예를 들어 노드의 자체 텍스트(즉, 자식 노드에 포함되지 않은 텍스트)에 단 하나의 숫자만 있는 경우, 예를 들어 조회 수, 댓글 수, 가격 등을 직접 추출. 여러 숫자가 있으면 첫 번째 연속된 숫자를 추출text()노드의 자체 텍스트를 추출, 자세한 내용은 https://github.com/zhegexiaohuozi/JsoupXpath/releases/tag/v2.4.1 참조node()모든 노드를 추출
AxisName: 'ancestor' // 현재 컨텍스트에서 노드의 조상 선택
| 'ancestor-or-self' // 현재 컨텍스트에서 노드의 조상 및 자기 자신 선택
| 'attribute' // 노드의 속성 추출 작업을 표시
| 'child' // 현재 컨텍스트에서 노드의 자식 노드 선택. 이는 XPath 기본 축으로, /div/li는 /div/child::li의 약자입니다.
| 'descendant' // 현재 컨텍스트에서 노드의 자손 선택
| 'descendant-or-self' // 현재 컨텍스트에서 노드의 자손 및 자기 자신 선택
| 'following' // 현재 컨텍스트에서 노드 뒤의 모든 노드 선택
| 'following-sibling' // 현재 컨텍스트에서 노드 뒤의 모든 형제 노드 선택
| 'parent' // 현재 컨텍스트에서 노드의 부모 노드 선택
| 'preceding' // 현재 컨텍스트에서 노드 앞의 모든 노드 선택
| 'preceding-sibling' // 현재 컨텍스트에서 노드 앞의 모든 형제 노드 선택
| 'self' // 현재 컨텍스트에서 선택
| 'following-sibling-one' // 컨텍스트에서 노드의 다음 형제 노드 선택 (JsoupXpath 확장)
| 'preceding-sibling-one' // 컨텍스트에서 노드의 이전 형제 노드 선택 (JsoupXpath 확장)
| 'sibling' // 모든 형제 선택 (JsoupXpath 확장)(개발 중...)
;
MINUS
: '-';
PLUS
: '+';
DOT
: '.';
MUL
: '*';
DIVISION
: '`div`';
MODULO
: '`mod`';
DOTDOT
: '..';
AT
: '@';
COMMA
: ',';
PIPE
: '|';
LESS
: '<';
MORE_
: '>';
LE
: '<=';
GE
: '>=';
START_WITH
: '^='; // `a^=b` 문자열 a가 문자열 b로 시작: a starts with b (JsoupXpath 확장)
END_WITH
: '$='; // `a$=b` a가 b로 끝남, a ends with b (JsoupXpath 확장)
CONTAIN_WITH
: '*='; // a가 b를 포함: a contains b (JsoupXpath 확장)
REGEXP_WITH
: '~='; // a의 내용이 정규표현식 b와 일치 (JsoupXpath 확장)
REGEXP_NOT_WITH
: '!~'; // a의 내용이 정규표현식 b와 일치하지 않음 (JsoupXpath 확장)
현재 JsoupXpath가 많이 사용되는 프로젝트나 조직은: SeimiCrawler입니다. 당신의 프로젝트에서도 JsoupXpath를 사용하고 이 목록에 추가되길 바란다면, 아래의 연락처를 통해 연락해 주세요. 이메일 형식은 다음과 같을 수 있습니다:
프로젝트 또는 조직 이름: XX
프로젝트 또는 조직 URL: http://xxx.xxx.cc